Batch normalization and layer normalization improve training stability and reduce sensitivity to initialization by normalizing intermediate activations.
When training a deep neural network, the distribution of inputs to each layer can change as the network’s weights are updated. If the weights become too large, the inputs to subsequent layers may grow excessively; if the weights shrink toward zero, the inputs may diminish accordingly. These shifts in input distributions make training more difficult, as each layer must continuously adapt to changing conditions. This phenomenon is known as internal covariate shift.
Normalization allows us to use much higher learning rates and be less careful about initialization.
Plain Normalization
If normalization (e.g., centering the activations to zero mean) is performed outside of the gradient descent step, the optimizer will remain “blind” to the normalization’s effects.
In formal terms, if the optimizer treats the mean-subtraction operation as a fixed constant, the gradient updates will fail to reflect the true dynamics of the network.
Consider a layer that computes and subsequently normalizes it: .
If the gradient is computed without considering how depends on , the optimizer will attempt to adjust to minimize the loss.
Because the normalization step subsequently subtracts the updated mean, the update is effectively cancelled. The output remains numerically identical to its state prior to the update:
Since the output—and consequently the loss—remains invariant despite the update, the optimizer will continue to increase in a futile attempt to reach a lower loss. This results in unbounded parameter growth while the network’s predictive performance stagnates.
To maintain training stability, normalization must be included within the computational graph so that gradients correctly capture its dependence on the parameters.
However, performing full whitening across all examples can be computationally expensive. This is why techniques like Batch Normalization and Layer Normalization are used instead.
Batch Normalization
Batch Normalization performs normalization for each training mini-batch.
In Batch Normalization, we normalize each scalar feature independently, by making it have the mean of zero and the variance of 1.
But simply normalizing each input of a layer may change what the layer can represent. The authors make sure that the transformation inserted in the network can represent the identity transform. Thus introducing:
The parameters here are learnable along with the original model parameters, and restore the representation power of the network.
By setting and , we could recover the original activations, if that were the optimal thing to do.
Algorithm 1: Batch Normalization Forward Pass
The forward pass of the Batch Normalization layer transforms a mini-batch of activations into a normalized and linearly scaled output . This process ensures that the input to subsequent layers maintains a stable distribution throughout training.
Input: Values of over a mini-batch: ; Parameters to be learned: .
Output: .
- Mini-batch Mean:
- Mini-batch Variance:
- Normalize:
- Scale and Shift:
Differentiation
To train the network using stochastic gradient descent, we must compute the gradient of the loss function with respect to the input and the learnable parameters and . This is achieved by applying the chain rule through the computational graph of the BN transform.
1. Gradients for Learnable Parameters
The parameters and are updated based on their contribution to all samples in the mini-batch:
- Gradient w.r.t. : Since , the gradient is the sum of the upstream gradients:
- Gradient w.r.t. : Since , the gradient is the sum of the product of the upstream gradient and the normalized input:
2. Gradient w.r.t. Intermediate Statistics
The gradient propagates backward from to the normalized value , and then to the batch statistics and :
- Gradient w.r.t. :
- Gradient w.r.t. : This accounts for how the variance affects every in the batch:
- Gradient w.r.t. : The mean affects the loss both directly through the numerator of and indirectly through the variance calculation:
3. Gradient w.r.t. Input
Finally, the gradient with respect to the original input is a combination of three paths: the direct path through , the path through the variance , and the path through the mean :
Training and Inference with Batch Normalization
The normalization of activations allows efficient training, but is neither necessary nor desirable during inference. Thus, once the network has been trained, we use the normalization using the population, as opposed to the mini-batch:
In practice, we use the fixed moving average calculated during training. During training, the mini-batch statistics are stochastic estimates of the true data distribution. The moving average serves as a stable, low-variance estimate of the population mean () and population variance ().
These running statistics are typically updated at each training step using a momentum coefficient (usually 0.9 or 0.99):
Layer Normalization
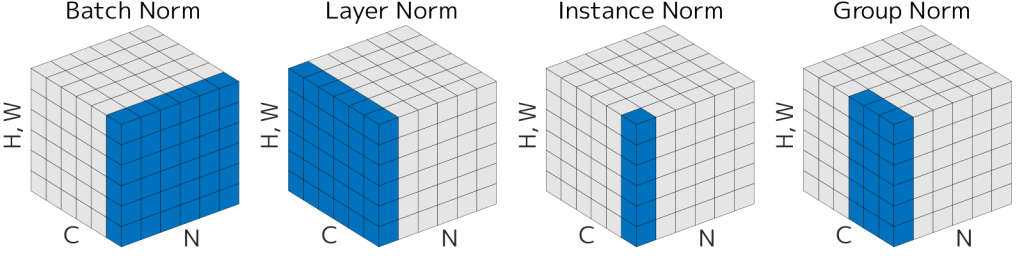
Layer Normalization (LayerNorm) is an alternative normalization technique that normalizes across the features of a single sample rather than across a mini-batch.
For an input vector , LayerNorm computes the mean and variance over the feature dimension, ensuring that each individual sample has zero mean and unit variance.
Unlike Batch Normalization, it does not depend on batch statistics, which makes it particularly suitable for recurrent neural networks and transformer architectures where batch sizes may be small or variable.
Similar to BatchNorm, LayerNorm includes learnable parameters and to scale and shift the normalized output, preserving the model’s representational capacity.
Reference
- Ioffe, S., & Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv:1502.03167.