With the disadvantages of the KNN algorithm, we need to come up with a more powerful approach. The new approach will have two major components: a score function that maps the raw data to class scores, and a loss function that quantifies the agreement between the predicted scores and the ground truth labels.
Score Function
The score function maps the pixel values of an image to confidence scores for each class.
As before, let’s assume a training dataset of images , each associated with a label . Here and .
That is, we have examples (each with a dimensionality ) and distinct categories.
We will define the score function that maps the raw image pixels to class scores.
Linear Classifier
We will start out with arguably the simplest possible function, a linear mapping.
In the above equation, we are assuming that the image has all of its pixels flattened out to a single column vector of shape [D x 1]. The matrix (of size [K x D]), and the vector (of size [K x 1]) are the parameters of the function.
The parameters in are often called the weights, and is called the bias vector because it influences the output scores, but without interacting with the actual data .
The input data are given and fixed. The goal is to set in such way that the computed scores match the ground truth labels across the whole training set.
Bias Tricks
We can combine the two sets of parameters into a single matrix that holds both of them by extending the vector with one additional dimension that always holds the constant - a default bias dimension.
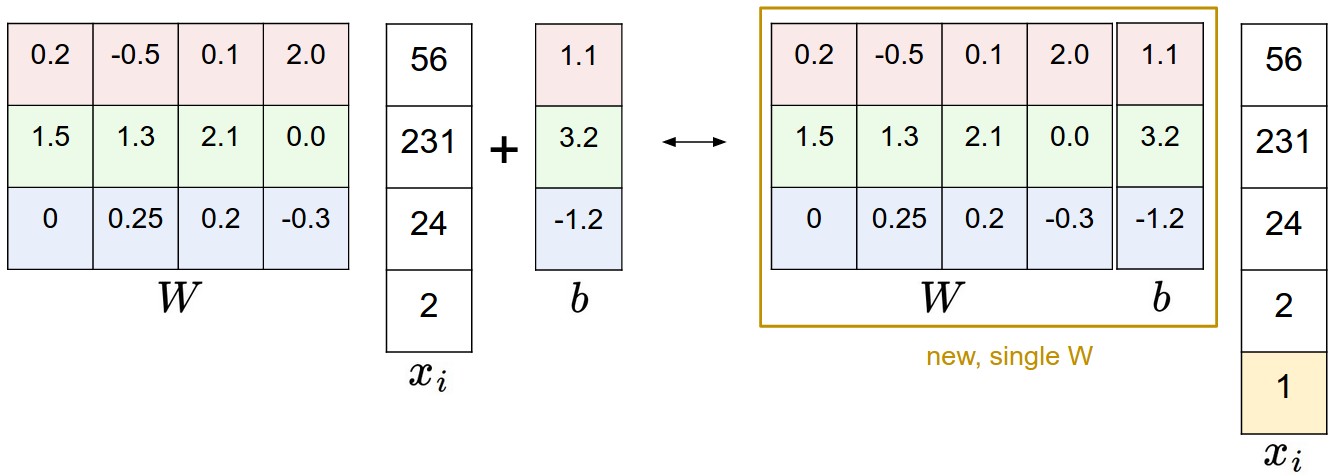
Image Data Preprocessing
In Machine Learning, it is a very common practice to always perform normalization of input features. In particular, it is important to center your data by subtracting the mean from every feature.
Loss Function
We will develop Multiclass Support Vector Machine (SVM) loss.
The score function takes the pixels and computes the vector of class scores, which we will abbreviate to (short for scores).
The Multiclass SVM loss for the i-th example is then formalized as follows:
The function accumulates the error of incorrect classes within Delta.
In summary, the SVM loss function wants the score of the correct class to be larger than the incorrect class scores by at least by (delta).
The threshold at zero max(0, -) function is often called the hinge loss. We also have squared hinge loss SVM (or L2-SVM), which uses the form max(0, -)² that penalizes violated margins more strongly.

Regularization
We wish to encode some preference for a certain set of weights W over others to remove this ambiguity. We can do so by extending the loss function with a regularization penalty . The most common regularization penalty is the squared L2 norm that discourages large weights through an elementwise quadratic penalty over all parameters:
Including the regularization penalty completes the full Multiclass Support Vector Machine loss, which is made up of two components: the data loss (which is the average loss over all examples) and the regularization loss.
Or in full form:
Penalizing large weights tends to improve generalization, because it means that no input dimension can have a very large influence on the scores all by itself. It keeps the weights small and simple. This can improve the generalization performance of the classifiers on test images and lead to less overfitting.
It prevents the model from doing too well on the training data.
Note that due to the regularization penalty we can never achieve loss of exactly 0.0 on all examples.
Practical Considerations
Setting Delta: It turns out that this hyperparameter can safely be set to in all cases. (The exact value of the margin between the scores is in some sense meaningless because the weights can shrink or stretch the differences arbitrarily.)
Binary Support Vector Machine: The loss for the i-th example can be written as
in this formulation and in our formulation control the same tradeoff and are related through reciprocal relation .
Other Multiclass SVM formulations: Multiclass SVM presented in this section is one of few ways of formulating the SVM over multiple classes.
Another commonly used form is the One-Vs-All (OVA) SVM which trains an independent binary SVM for each class vs. all other classes. Related, but less common to see in practice is also the All-vs-All (AVA) strategy.
The last formulation you may see is a Structured SVM, which maximizes the margin between the score of the correct class and the score of the highest-scoring incorrect runner-up class.
Softmax Classifier
In the Softmax Classifier, we now interpret these scores as the unnormalized log probabilities for each class and replace the hinge loss with a cross-entropy loss that has the form:
where we are using the notation to mean the j-th element of the vector of class scores .
The function is called the softmax function: It takes a vector of arbitrary real-valued scores (in ) and squashes it to a vector of values between zero and one that sum to one.
Information Theory View
The cross-entropy between a “true” distribution and an estimated distribution is defined as:
Minimizing Cross-Entropy is equivalent to minimizing the KL Divergence.
Because the true distribution is fixed (its entropy is zero in this scenario), minimizing cross-entropy is the same as forcing the predicted distribution to look exactly like the true distribution .
The Softmax Loss objective is to force the neural network to output a probability distribution where the correct class has a probability very close to 1.0, and all other classes are close to 0.0.
Information Theory Supplementary
Information Entropy measures the uncertainty or unpredictability of a random variable.
The more unpredictable an event is (lower probability), the more information is gained when it occurs, and the higher the entropy. Conversely, if an event has a probability of 1 (certainty), its entropy is 0.
For a discrete random variable with possible outcomes and probabilities , the entropy is defined as:
Cross Entropy measures the total cost of using distribution to represent distribution .
Minimizing the cross-entropy is mathematically equivalent to minimizing the KL Divergence. It forces the predicted distribution to become as close as possible to the true distribution .
Probabilistic View
The formula maps raw scores to a range of such that the sum of all class probabilities equals 1.
Using the Cross-Entropy loss function during training is equivalent to maximizing the likelihood of the correct class.
Numeric Stability
Dividing large numbers can be numerically unstable, so it is important to use a normalization trick.
A common choice for is to set . This simply states that we should shift the values inside the vector so that the highest value is zero. In code:
1 | f = np.array([123, 456, 789]) # example with 3 classes and each having large scores |
Note
To be precise, the SVM classifier uses the hinge loss, or also sometimes called the max-margin loss.
The Softmax classifier uses the cross-entropy loss.
SVM vs Softmax
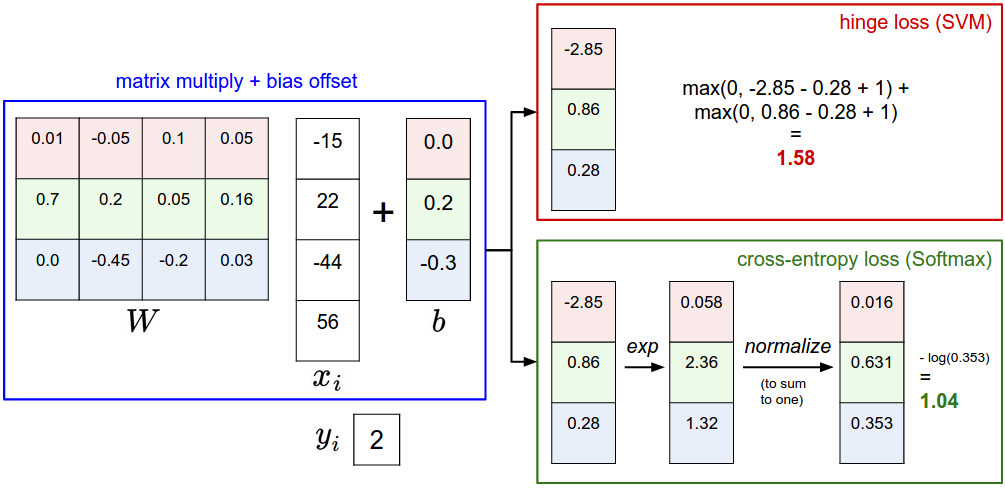
The SVM interprets these as class scores and its loss function encourages the correct class to have a score higher by a margin than the other class scores.
The Softmax classifier instead interprets the scores as (unnormalized) log probabilities for each class and then encourages the (normalized) log probability of the correct class to be high (equivalently the negative of it to be low).
Softmax classifier provides “probabilities” for each class.
The “probabilities” are dependent on the regularization strength. They are better thought of as confidences where the ordering of the scores is interpretable.
In practice, SVM and Softmax are usually comparable. Compared to the Softmax classifier, the SVM is a more local objective.
The Softmax classifier is never fully happy with the scores it produces: the correct class could always have a higher probability and the incorrect classes always a lower probability and the loss would always get better.
However, the SVM is happy once the margins are satisfied and it does not micromanage the exact scores beyond this constraint.